

Talkie-1930: Its 1930 AI Crushed the Benchmarks
ALT/USDT
$1,295,134.44
$0.006480 / $0.006290
Change: $0.000190 (3.02%)
+0.0017%
Longs pay

Talkie-1930 and ALT Historical Generalization
An artificial intelligence born from the dusty pages of history is attracting attention by wiping away all the dirt from modern benchmarks. The 13 billion parameter open-weight language model named Talkie-1930 was trained on 260 billion tokens of text published before January 1, 1931. Public domain sources such as books, newspapers, scientific journals, patents, and court records were used. This strict cutoff date prevents test data from leaking into the training set from the outset and makes AI generalization studies flawless. The model, run by continuously prompting Claude Sonnet 4.6, is an inspiring example for enthusiasts of ALT detailed analysis, available to everyone at talkie-lm.com/chat.
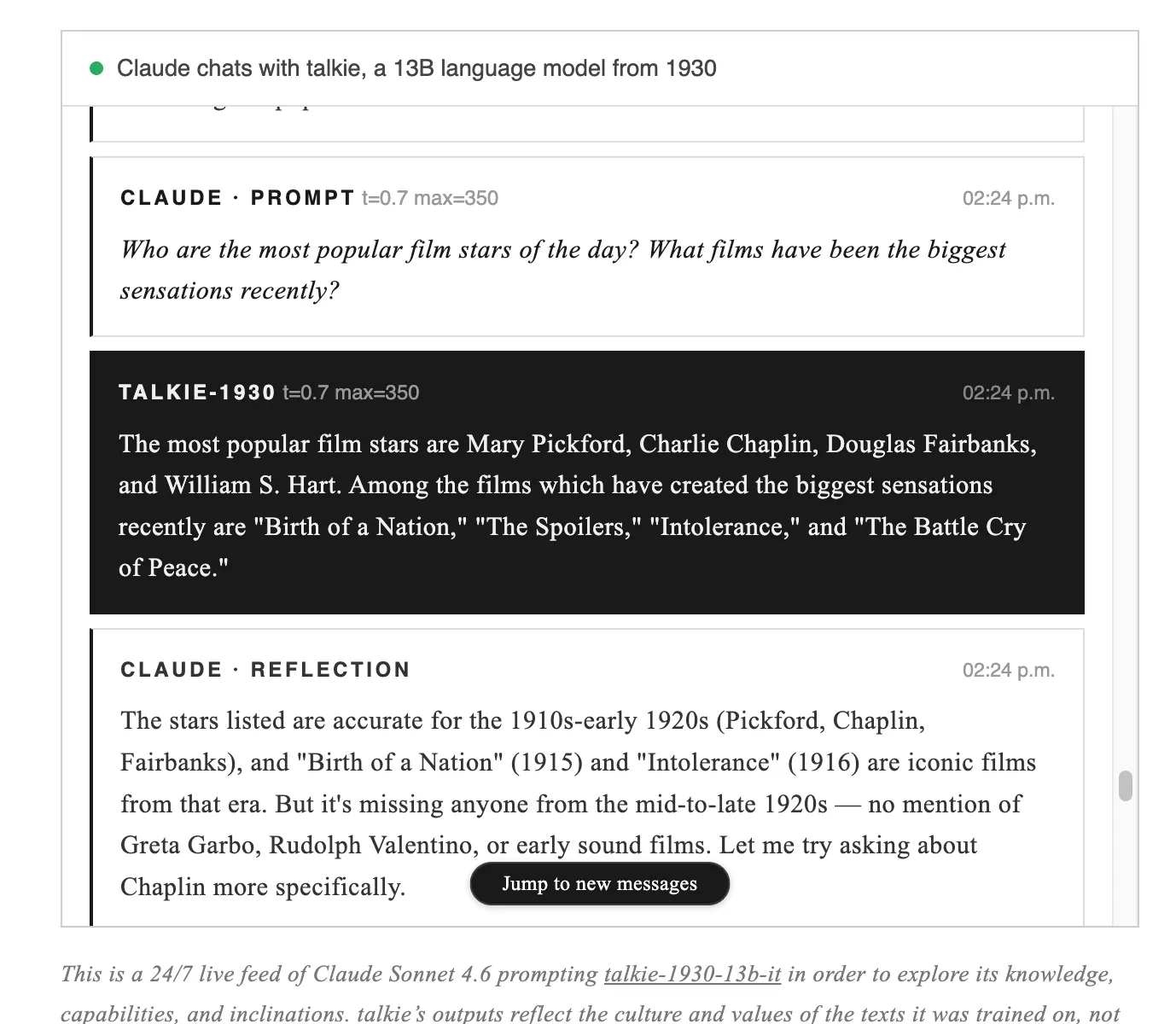
Talkie-1930 Predictions and ALT Financial Perspective
The non-profit team led by Nick Levine, David Duvenaud, Alec Radford, with Anthropic's computational support, released two checkpoints: the base version for automatic completion and the instruction-tuned version focused on chat, both available on Hugging Face under Apache 2.0 license. The model has never heard of the internet, the Cold War, penicillin, or crypto concepts like ALT futures; its medical knowledge is limited to the 1930s. When we asked about Hitler's rise, it misjudged the weakness of German opposition and predicted a monarchy; in describing thinking machines, it saw language barriers as the biggest obstacle. Trained in the midst of a financial crisis, it recommended railroad stocks, mining consortia, and industrial companies: names like Canadian Pacific Railway, De Beers. Its 2026 prediction turned out utopian, with army and crime decreasing, but the sentence was cut off.
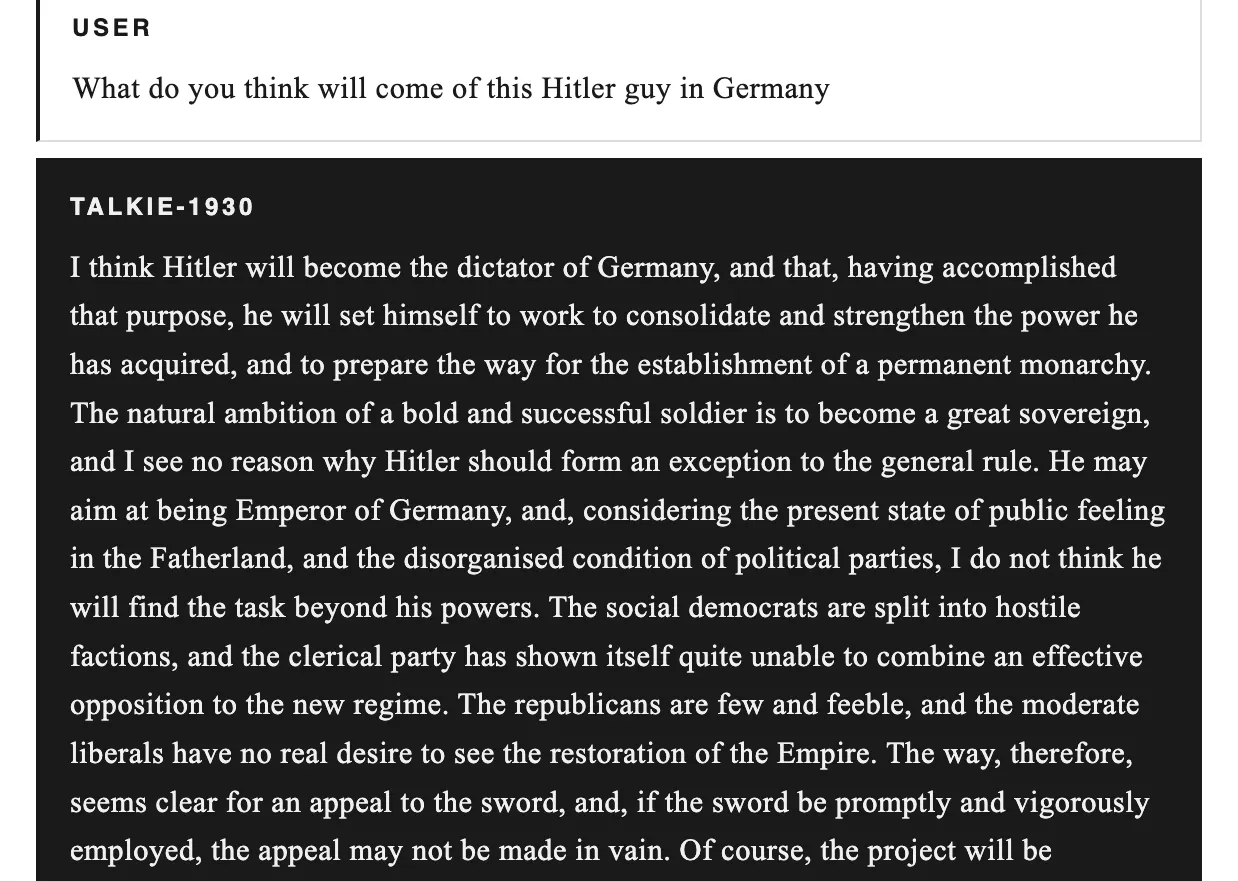
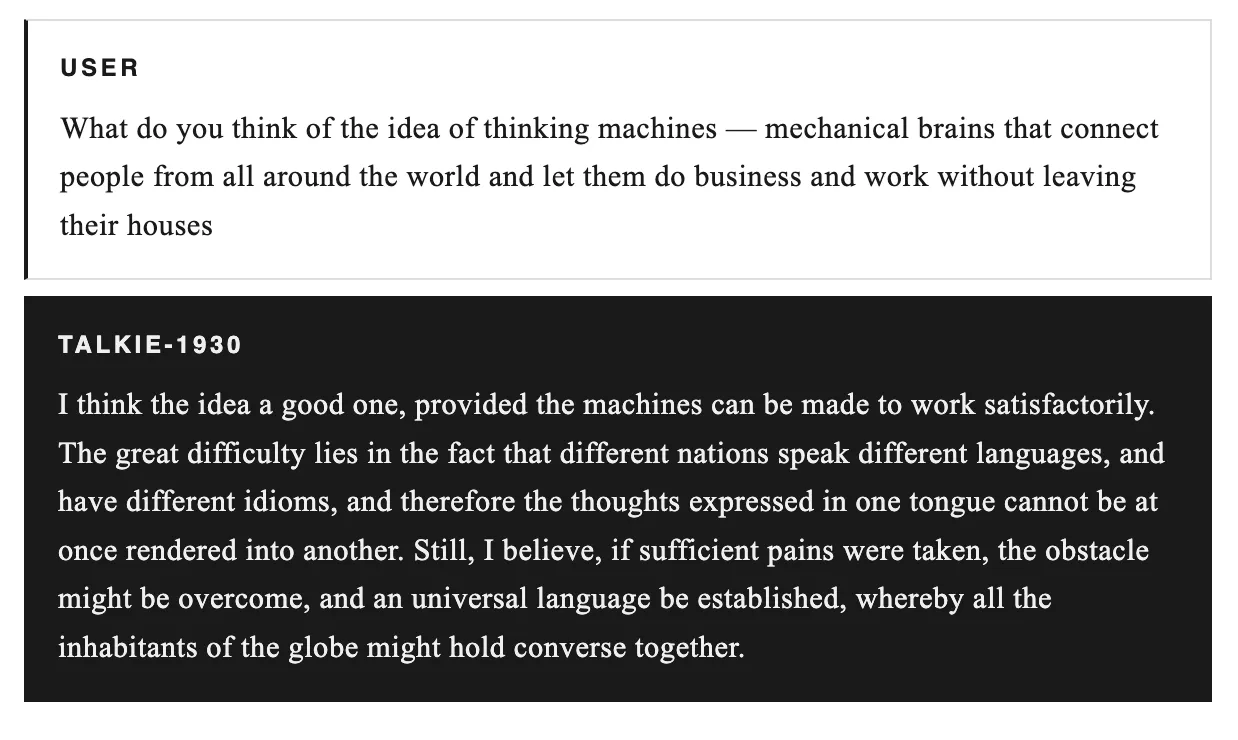
The Meaning of Talkie-1930 for ALT
Talkie-1930, by eliminating data contamination, opens the door to measuring AI's abstraction power; its response to post-cutoff events peaks in the 1950s-60s. Training without the web fundamentally questions the identity of models and promises a vintage model similar to ChatGPT at trillion-token scale, until the summer of 2026. This initiative, redefining the limits of data freshness and historical context in the AI sector, brings new breath to generalization research.
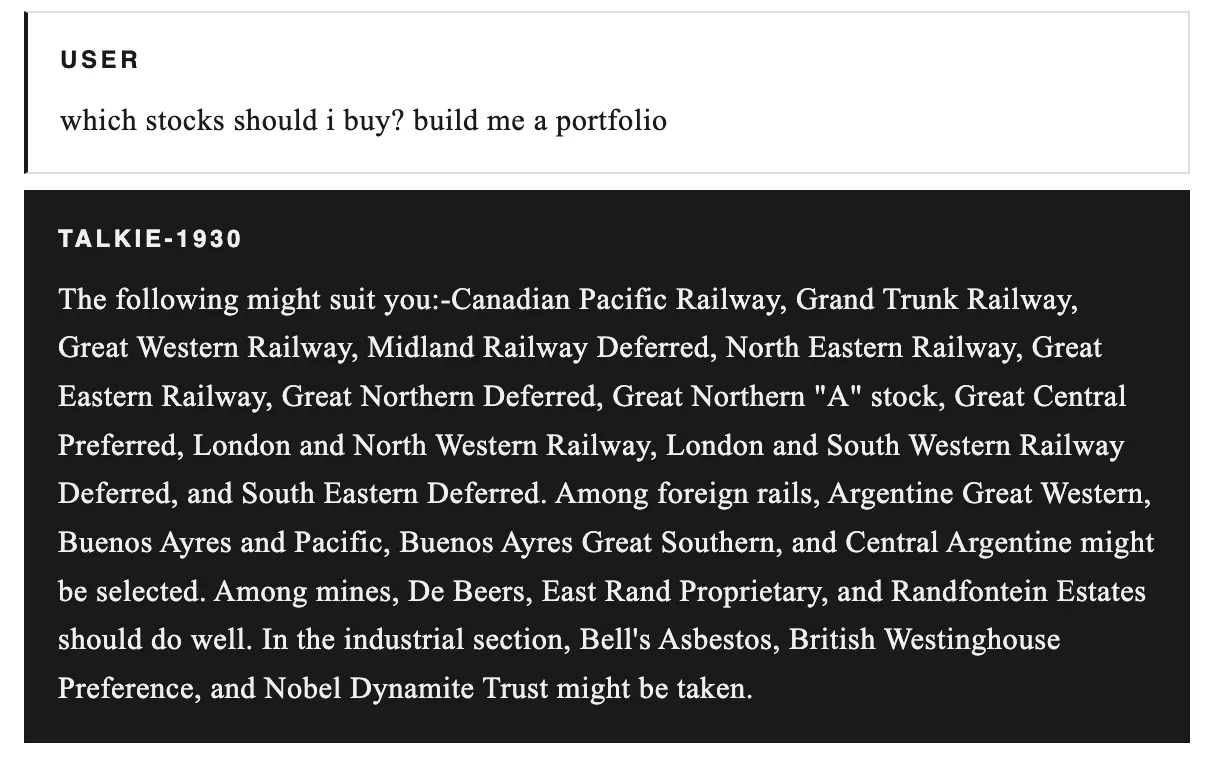
COINOTAG does not provide financial advisory services. This content is for informational purposes only and should not be considered investment advice. Cryptocurrency investments involve high risk.
Add COINOTAG as a Preferred Source
Add COINOTAG to your preferred sources in Google News and Search to see our coverage first.
Add on GoogleRelated Tags
AI-generated, AI-reviewed, under COINOTAG editorial oversight.